
El aprendizaje profundo ha revolucionado campos como la visión artificial, el procesamiento de lenguaje natural y más. Cuando se desarrolla un modelo de red neuronal profunda para una nueva tarea, tenemos dos opciones principales: ajustar un modelo preentrenado existente o entrenar un nuevo modelo desde cero. Ambos enfoques tienen pros y contras. En esta guía completa de más de 8000 palabras, exploraremos en profundidad el ajuste fino frente al entrenamiento desde cero para comprender cuándo destaca cada técnica.
Puntos claves del articulo
La idea clave es que el ajuste fino sobresale dado datos y tiempo de entrenamiento limitados, mientras que el entrenamiento desde cero se beneficia de grandes conjuntos de datos y recursos informáticos. Considere factores como el tamaño de los datos, la similitud del problema, el tiempo de entrenamiento y la disponibilidad de hardware al elegir un enfoque.
El ajuste fino es excelente para implementaciones rápidas y conjuntos de datos pequeños, pero permite una personalización limitada. El entrenamiento desde cero permite la personalización completa del modelo dado suficientes datos y computación. Piense en su caso de uso específico, los recursos disponibles y los objetivos de rendimiento para elegir la técnica correcta.
En resumen:
- Ajuste fino – Conjuntos de datos pequeños, implementación rápida, aprovecha el conocimiento de expertos
- Entrenamiento desde cero – Grandes conjuntos de datos, permite la personalización total, requiere más recursos
Ahora profundicemos en cómo funciona cada enfoque, sus pros y contras, cuándo brilla cada técnica y recomendaciones para elegir entre ellas.
Contenidos: Ajuste Fino vs Entrenamiento desde Cero para Modelos de Aprendizaje Profundo
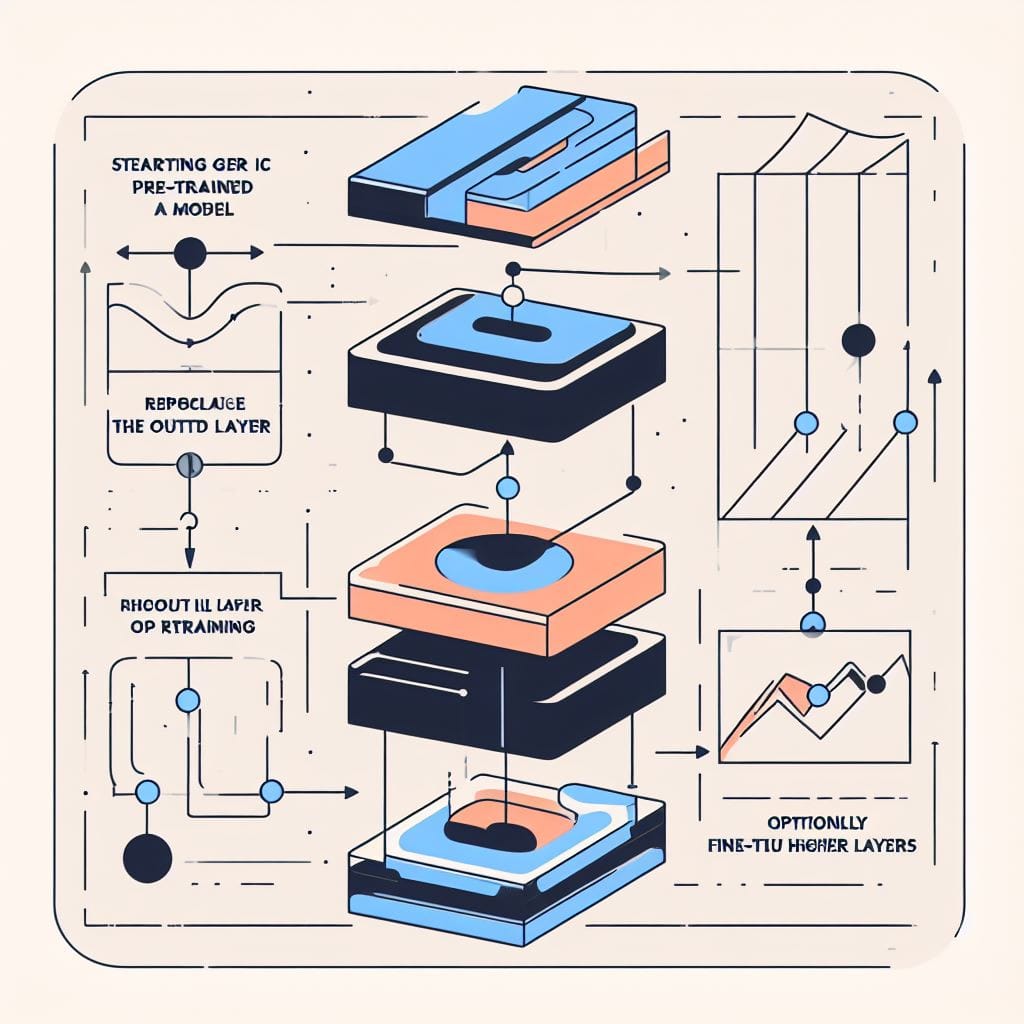
Cómo Funciona el Ajuste Fino
El ajuste fino es una técnica de transferencia de aprendizaje que adapta una red neuronal preentrenada a una nueva tarea mediante el reentrenamiento de sus pesos en nuevos datos. Aquí hay una descripción general del proceso:
Pasos para el Ajuste Fino de una Red Neuronal
- Comience con un modelo base preentrenado en un gran conjunto de datos genérico como ImageNet. Estos modelos han aprendido representaciones útiles para muchas tareas.
- Reemplace y vuelva a entrenar la capa de salida del modelo preentrenado en un conjunto de datos para su nueva tarea específica.
- Opcionalmente ajuste los pesos de las capas preentrenadas para que se adapten a su conjunto de datos. Por lo general, solo algunas de las capas superiores necesitan adaptación.
- Conserve la mayoría de los pesos preentrenados fijos, permitiendo que el modelo se adapte a nuevos datos con menos ejemplos y menos cómputo que el entrenamiento desde cero.
Por ejemplo, podría ajustar finamente un modelo de clasificación de imágenes preentrenado como ResNet-50 para nuevos tipos de objetos volviendo a entrenar la capa de salida y capas superiores en nuevos datos de imágenes etiquetados.

Descripción general del proceso de ajuste fino: adaptar solo las capas superiores de un modelo pre-entrenado
¿Por qué funciona el ajuste fino?
El ajuste fino se basa en estas ideas clave del aprendizaje profundo:
- Las primeras capas en las redes neuronales aprenden características genéricas útiles para muchas tareas, como bordes en imágenes. Las capas posteriores se especializan en detalles.
- El conocimiento adquirido en grandes conjuntos de datos se transfiere bien a nuevos problemas relacionados.
- Se necesita un reentrenamiento mínimo para adaptarse a nuevos datos, ya que las características iniciales siguen siendo relevantes.
Al aprovechar el extenso preentrenamiento y volver a entrenar solo las capas superiores, el ajuste fino permite una implementación rápida incluso con datos limitados. A continuación, echemos un vistazo más de cerca a algunos de los principales beneficios del ajuste fino.

Beneficios del Ajuste Fino de Redes Neuronales
Estos son algunos de los principales beneficios de utilizar el ajuste fino para el aprendizaje profundo:
Requiere Menos Datos
Uno de los mayores atractivos del ajuste fino es que puede funcionar bien incluso con datos de entrenamiento limitados.
Por ejemplo, las técnicas de ajuste fino han demostrado un rendimiento sólido en benchmarks con solo cientos o miles de ejemplos de entrenamiento por clase. En contraste, el entrenamiento de grandes redes neuronales desde cero generalmente requiere decenas o cientos de miles de ejemplos para alcanzar la máxima precisión.
Esta eficiencia de datos se debe a que el modelo preentrenado proporciona un conocimiento previo sustancial sobre características, representaciones y motivos arquitectónicos. Su conjunto de datos solo se necesita para adaptar este conocimiento previo al nuevo problema, lo que requiere menos datos que aprender completamente desde cero.
Permite una Implementación Rápida
Otro beneficio del ajuste fino es que permite adaptar rápidamente un modelo preentrenado a nuevas tareas. El ajuste fino es sencillo de implementar: simplemente reemplace la capa de salida del modelo preentrenado y vuelva a entrenarlo en su conjunto de datos objetivo.
Se requiere muy poca codificación y se evita tener que diseñar una arquitectura de modelo completa desde cero. Esto simplifica y acelera el proceso de construcción del modelo.
Por ejemplo, podría ajustar finamente un modelo BERT preentrenado para la clasificación de texto en solo unas horas. En comparación, el entrenamiento de un modelo NLP grande desde cero podría llevar semanas.
Aprovecha los Conocimientos de Expertos
El ajuste fino también le permite beneficiarse de todo el conocimiento experto utilizado para diseñar, entrenar y validar los modelos pre-entrenados.
Modelos de vanguardia como BERT y ResNet fueron meticulosamente elaborados por investigadores e ingenieros durante muchos años. Esto incluye elementos como:
- Diseño de arquitectura neuronal
- Optimización de hiperparámetros
- Extracción de características de propósito general
Al ajustar estos modelos, obtiene todo este conocimiento incorporado para su problema sin necesidad de adquirir el mismo nivel de recursos y experiencia. ¡De pie sobre los hombros de gigantes!
Desempeño Sólido en Tareas Relacionadas
En general, el ajuste fino sobresale cuando su tarea está estrechamente relacionada con el dominio del problema del modelo original. Este estrecho alineamiento permite una mayor transferencia de conocimiento útil.
Por ejemplo, ajustar un clasificador de imágenes genérico para reconocer nuevos tipos de objetos. O adaptar un modelo entrenado en artículos de noticias para clasificar texto de redes sociales.
Cuanto más relacionado sea su problema, mejores resultados verá del ajuste fino, ya que se aplica más del conocimiento preentrenado.
En resumen, el ajuste fino ofrece grandes ventajas como requerir menos datos, implementación rápida, aprovechar sistemas expertos y un buen rendimiento en tareas relacionadas. A continuación, veamos algunos casos de uso ideales.
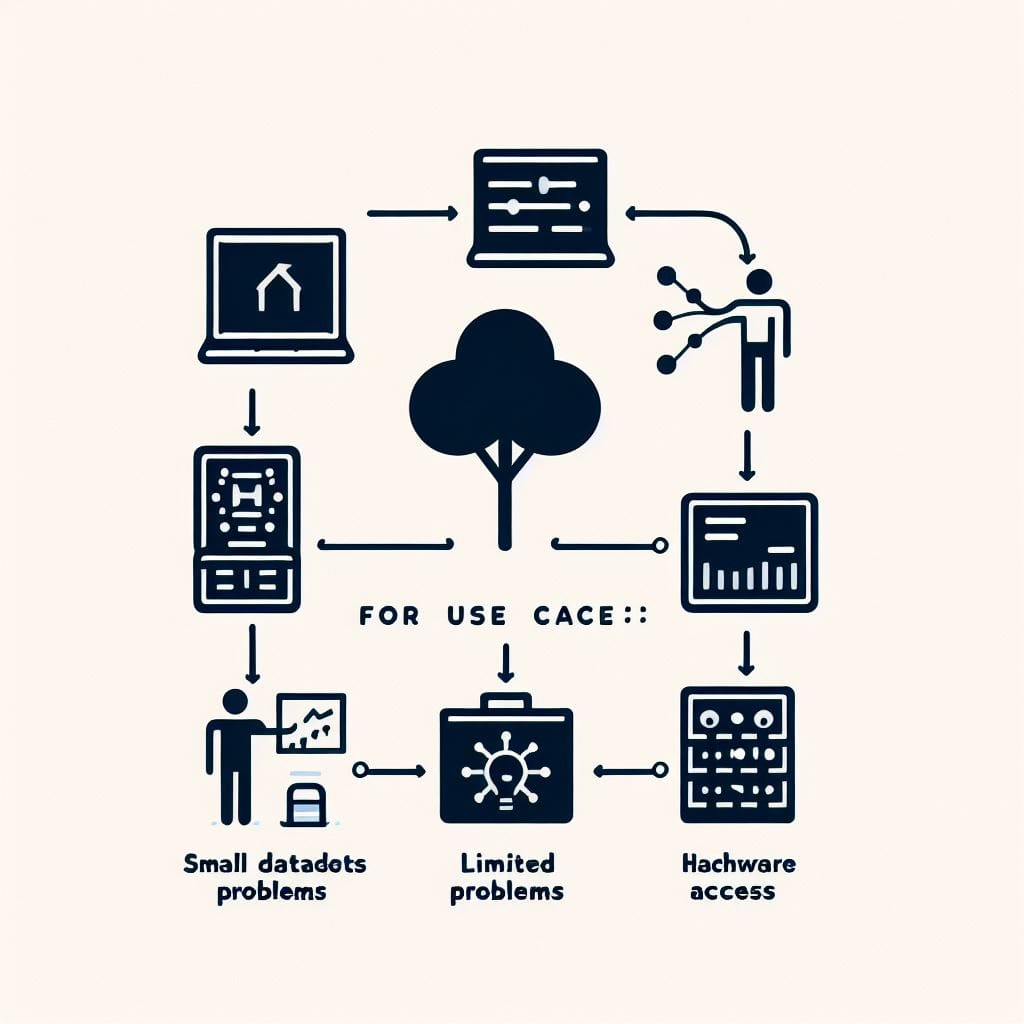
Casos de Uso Ideales para el Ajuste Fino
Basado en sus fortalezas, estos son algunos ejemplos de tareas y áreas de aprendizaje automático donde brilla el ajuste fino de modelos preentrenados:
Datos de Entrenamiento Limitados
El ajuste fino sobresale cuando solo tiene conjuntos de datos pequeños o medianos disponibles.
Por ejemplo, el ajuste fino es ideal cuando solo tiene unos pocos cientos o miles de ejemplos etiquetados. Este régimen de datos es muy común para problemas como:
- Condiciones médicas raras
- Categorías de productos de nicho
- Idiomas con pocos recursos
- Procesos industriales específicos
El ajuste fino permite construir modelos altamente precisos transfiriendo conocimiento de modelos pre-entrenados incluso con datos específicos del problema limitados.
Adaptación Rápida a Problemas Similares
El ajuste fino es excelente para adaptarse rápidamente a nuevos conjuntos de datos y casos de uso que son muy similares a la tarea del modelo original.
Por ejemplo:
- Nuevas categorías de detección de objetos
- Análisis de sentimiento para dominios relacionados
- Agregar capacidades a un asistente virtual
- Detectar nuevos tipos de malware
Dado que el conocimiento preentrenado casi se aplica directamente en estos casos, el ajuste fino ofrece una iteración y desarrollo rápidos.
Cuando la Personalización del Modelo es Limitada
El ajuste fino depende de arquitecturas de modelos estándar pre-entrenados. Esto restringe la personalización del modelo, pero proporciona una iteración rápida y aprovecha el conocimiento de la comunidad.
El ajuste fino es ideal si no necesita arquitecturas de modelos especializados o no tiene recursos para realizar una extensa exploración de modelos.
Acceso a Hardware Acelerado
El entrenamiento de modelos pre-entrenados a gran escala requiere recursos informáticos significativos. El ajuste fino le permite aprovechar estos modelos sin acceso a infraestructura a gran escala.
Por ejemplo, ajuste fino de BERT para una tarea de texto en lugar de entrenar un transformer enorme desde cero. Esto permite aprovechar los avances recientes incluso con acceso limitado al hardware.
En resumen, el ajuste fino sobresale en configuraciones con datos limitados, problemas altamente relacionados, personalización de modelos restringida y puede funcionar sin hardware acelerado a gran escala.
Limitaciones y Desventajas del Ajuste Fino
Si bien el ajuste fino tiene muchos beneficios, también tiene algunas limitaciones a considerar:
- Arquitectura de Modelo Restringida – El ajuste fino depende de las arquitecturas de modelos preentrenados existentes. Esto restringe la flexibilidad para la personalización del modelo.
- Transferencia Negativa – El ajuste fino puede tener un rendimiento peor que el entrenamiento desde cero si el conocimiento del modelo original no es aplicable.
- Pre-entrenamiento Computacionalmente Costoso – Si bien el propio ajuste fino es eficiente, la pre-formación de modelos conlleva costos y huella de carbono elevados.
- Amplifica los Sesgos – Los modelos pueden amplificar los sesgos problemáticos presentes en los datos de entrenamiento originales.
- Modelos Caja Negra – Desafíos de interpretabilidad dado que los internos del modelo provienen del pre-entrenamiento opaco.
Comprender estas limitaciones ayuda a identificar cuándo pueden preferirse alternativas como el entrenamiento desde cero. A continuación, nos sumergiremos más en profundidad en esa técnica.
Entrenamiento de Redes Neuronales desde Cero
La alternativa al ajuste fino es descartar cualquier modelo pre-entrenado y entrenar su red neuronal desde cero en su conjunto de datos:
Pasos para el Entrenamiento de un Modelo desde Cero
- Inicialice una red neuronal aleatoriamente usando esquemas de inicialización Xavier o He.
- Entrene todas las capas de la red conjuntamente en su conjunto de datos de extremo a extremo usando descenso de gradiente estocástico.
- Aprenda todas las características y representaciones directamente en sus datos de entrenamiento.
- Requiere mucho más datos y tiempo de entrenamiento en comparación con el ajuste fino.
Por ejemplo, entrenar directamente una gran red neuronal convolucional en datos de imágenes para clasificar mascotas versus vida silvestre.

Proceso para entrenar un modelo desde cero
El entrenamiento desde cero descarta cualquier supuesto previo y aprende directamente de los datos proporcionados. A continuación, echemos un vistazo a algunos de los principales beneficios de este enfoque.

Beneficios del Entrenamiento de Modelos de Aprendizaje Profundo desde Cero
Estos son algunos de los principales beneficios de entrenar modelos desde cero:
Puede Tener un Mejor Rendimiento Dado Suficientes Datos
Un gran atractivo del entrenamiento desde cero es que en última instancia puede lograr un mejor rendimiento que el ajuste fino, dado suficientes datos de entrenamiento.
Dado que el modelo aprende características puramente basadas en sus datos de entrenamiento, con suficientes ejemplos puede superar el rendimiento de los modelos ajustados finamente. En benchmarks con millones de ejemplos de entrenamiento por clase como ImageNet, los modelos entrenados desde cero siguen siendo estado del arte.
El ajuste fino puede alcanzar un techo de rendimiento ya que el pre-entrenamiento nunca se realiza en su problema exacto. El entrenamiento desde cero no tiene esta limitación teórica.
Permite la Personalización Completa del Modelo
El entrenamiento desde cero también proporciona flexibilidad total para definir arquitecturas de modelos especializados para su problema.
Esta personalización permite crear modelos compactos adaptados a sus objetivos y restricciones. Por ejemplo, diseñar modelos pequeños para implementación en dispositivos periféricos.
El ajuste fino depende de arquitecturas estándar como ResNet y BERT, lo que restringe la exploración arquitectónica.
Evita la Transferencia Negativa
Si su problema es muy diferente de la tarea de pre-entrenamiento del modelo original, el ajuste fino puede provocar una transferencia negativa. Esto sucede cuando el conocimiento irrelevante degrada el rendimiento.
El entrenamiento desde cero evita este problema al aprender solo de sus datos de entrenamiento. No se incorporan suposiciones basadas en modelos pre-entrenados.
Puede ser más Interpretable
Dado que todo el conocimiento del modelo proviene directamente de sus datos, el entrenamiento desde cero puede proporcionar una mayor interpretabilidad. Analizar la importancia de características y patrones de activación es más simple sin pre-entrenamiento heredado.
El ajuste fino puede exhibir un comportamiento más opaco de caja negra dado que se desconocen los internos del modelo pre-entrenado.
En resumen, las principales ventajas del entrenamiento desde cero son un mejor rendimiento máximo, personalización completa del modelo, evitar la transferencia negativa y una mayor interpretabilibilidad.
Casos de Uso Ideales para el Entrenamiento desde Cero
Basado en sus puntos fuertes, estos son buenos casos de uso para entrenar redes neuronales desde cero:
Suficientes Datos de Entrenamiento Disponibles
Si puede recopilar un gran conjunto de datos supervisado para su problema, el entrenamiento desde cero funciona muy bien.
Por ejemplo, benchmarks con cientos de miles o millones de ejemplos etiquetados como:
- Conjuntos de datos de recomendación de productos
- Grandes corpus de texto, código o gráficos
- Datos médicos para condiciones comunes
- Conjuntos de datos de visión artificial de propósito general
Con grandes conjuntos de datos, el entrenamiento desde cero puede superar el ajuste fino al aprender directamente de abundantes ejemplos.
Problemas muy Diferentes a los Datos de Pre-Entrenamiento
Si su problema es muy diferente de los modelos pre-entrenados disponibles, el entrenamiento desde cero evita la transferencia negativa de conocimiento irrelevante.
Por ejemplo, dominios completamente diferentes como:
- Datos de física de partículas
- Tareas de síntesis molecular novedosas
- Reconocimiento de fenómenos exóticos
- Traducción de idiomas antiguos
El entrenamiento de modelos personalizados desde cero garantiza la máxima relevancia para su caso de uso real.
Requiere Arquitecturas de Modelos Especializadas
El entrenamiento desde cero permite la flexibilidad total para personalizar arquitecturas de redes neuronales para su problema.
Esto permite crear modelos compactos para dispositivos móviles, nuevas topologías de red como transformers o introducir restricciones estructurales específicas del problema.
El ajuste fino se limita a arquitecturas de modelos pre-entrenados estándar.
Aprovechando los Últimos Avances como Modelos de Difusión
El entrenamiento desde cero permite incorporar los últimos avances en aprendizaje profundo.
Por ejemplo, modelos de difusión para generación de imágenes o autoatención dispersa para sistemas de recomendación. El ajuste fino lo encierra en paradigmas de modelos más antiguos.
Acceso a Recursos Informáticos a Gran Escala
El entrenamiento de grandes redes neuronales es muy intensivo computacionalmente. Si tiene acceso a recursos como 100 GPUs o TPUs, el entrenamiento desde cero se vuelve más viable.
Aprovechar supercomputadoras permite entrenar enormes modelos personalizados utilizando las técnicas más recientes.
En resumen, el entrenamiento desde cero sobresale dado grandes conjuntos de datos, dominios muy diferentes, la necesidad de personalización de modelos, aprovechando las técnicas más recientes y el acceso a hardware acelerado.

Limitaciones y Desventajas del Entrenamiento desde Cero
Si bien el entrenamiento desde cero tiene muchos beneficios, algunas desventajas a considerar son:
- Requiere Muchos más Datos – A menudo se necesitan grandes conjuntos de datos con cientos de miles o millones de ejemplos.
- Computacionalmente Costoso – El entrenamiento de grandes redes neuronales requiere recursos informáticos sustanciales. La exploración de modelos es costosa.
- Consumidor de Tiempo – El entrenamiento de arquitecturas personalizadas desde cero es lento dada la necesidad de experimentación.
- Diseño de Arquitectura Difícil – Crear arquitecturas de redes neuronales desde cero es desafiante y requiere habilidades especializadas.
- Repite el Esfuerzo de la Comunidad – Resolviendo desafíos de pre-entrenamiento ya abordados por modelos públicos.
Tener en cuenta estas limitaciones ayuda a identificar casos en los que el ajuste fino puede ser preferible. A continuación, compararemos directamente los dos enfoques.

Ajuste Fino vs Entrenamiento desde Cero: Comparación Directa
Resumamos las diferencias clave entre el ajuste fino y el entrenamiento de modelos de aprendizaje profundo desde cero:
| Ajuste Fino | Entrenamiento desde Cero | |
|---|---|---|
| Requisitos de Datos | Menos datos necesarios (100 a 1000 ejemplos) | Se necesitan grandes conjuntos de datos (100,000+ ejemplos) |
| Tiempo de Implementación | Rápido (horas a días) | Lento (semanas a meses) |
| Cómputo Necesario | Bajo | Alto |
| Personalización del Modelo | Arquitectura restringida | Personalización completa |
| Potencial de Rendimiento | Techo más bajo | Techo más alto |
| Similitud del Problema | Excelente en dominios similares | Mejor en dominios diferentes |
En resumen, el ajuste fino brilla con pequeños conjuntos de datos e iteración rápida, mientras que el entrenamiento desde cero se beneficia de abundantes datos y cómputo para la personalización.
Ningún enfoque es universalmente mejor: sopesar sus compensaciones frente a sus prioridades y restricciones específicas. A menudo, un enfoque combinado funciona mejor, como pre-entrenar bloques de construcción de redes neuronales desde cero y luego ajustar todo el modelo.
A continuación, proporcionaremos recomendaciones concretas sobre la elección de un enfoque en función de su situación.
Cómo Decidir: Ajuste Fino vs. Entrenamiento desde Cero
Al determinar si ajustar un modelo pre-entrenado o entrenar un modelo personalizado desde cero, considere los siguientes factores clave:
Tamaño del Conjunto de Datos de Entrenamiento Disponible
Si solo tiene datos limitados (100 a 1000 ejemplos), se prefiere el ajuste fino. Los modelos pre-entrenados proporcionan representaciones iniciales robustas que permiten la adaptación con datos mínimos.
Si tiene abundancia de datos (100,000+ ejemplos), el entrenamiento desde cero puede ser excelente. El modelo puede aprender directamente de extensos ejemplos adaptados a su problema.
Similitud con el Dominio de Entrenamiento del Modelo Original
Si su problema se asemeja estrechamente a la tarea de pre-entrenamiento, el ajuste fino se beneficia de una mayor transferencia de aprendizaje. Por ejemplo, ambos implican analizar fotos.
Si su problema es muy diferente, el entrenamiento desde cero evita la transferencia negativa. Por ejemplo, adaptar un modelo de imagen a datos de audio puede no funcionar bien.
Requisitos de Tiempo de Entrenamiento
Si necesita una solución rápidamente, aproveche el ajuste fino para una iteración rápida. El entrenamiento de arquitecturas personalizadas agrega un tiempo de diseño significativo.
Si el tiempo de entrenamiento es flexible, el entrenamiento desde cero permite la exploración y optimización completas del modelo. Presupuestar más tiempo de desarrollo.
Recursos Informáticos Disponibles
Si los recursos informáticos son limitados, ajuste finamente para evitar un entrenamiento costoso. El ajuste fino permite aprovechar grandes modelos pre-entrenados sin acceso a infraestructura a escala.
Con acceso a hardware acelerado como 100+ GPU, el entrenamiento de modelos personalizados se vuelve viable. Invierta en la exploración de modelos.
Necesidad de Arquitecturas de Modelos Especializadas
Si los modelos estándar satisfacen sus necesidades, el ajuste fino proporciona resultados sólidos rápidamente. Permanecer con arquitecturas conocidas como ResNet y BERT.
Para problemas muy restringidos como aplicaciones móviles, entrene modelos compactos especializados desde cero. Diseñar topologías de redes neuronales personalizadas.
Siempre hay excepciones, pero analizar estos factores clave proporciona una guía para decidir sobre un enfoque. Combine el empirismo, probando ambos para comparar, con consideraciones teóricas para tomar la mejor decisión.
Consejos para un Ajuste Fino y Entrenamiento desde Cero Efectivos
Siga estos consejos al implementar el ajuste fino o el entrenamiento de modelos de aprendizaje profundo desde cero:
Consejos de Ajuste Fino
- Coincidir la capacidad del modelo con el conjunto de datos – Usar modelos pre-entrenados más pequeños para conjuntos de datos diminutos. Modelos más grandes para conjuntos de datos más grandes (10k+ ejemplos).
- Congelar las primeras capas – Por lo general, solo ajustar finamente las capas superiores cerca de la salida del modelo.
- Usar normalización por lotes – Ayuda a estabilizar las actualizaciones de las estadísticas por lotes pre-entrenadas.
- Tasas de aprendizaje más bajas – Ajustar finamente lentamente usando tasas de aprendizaje pequeñas como 1e-5 o 1e-6.
- Monitorear el sobre-ajuste – Observar la pérdida de validación, detenerse temprano si el modelo comienza a sobre-ajustarse.
Consejos de Entrenamiento desde Cero
- Simplificar arquitecturas – Usar bloques de construcción establecidos como convoluciones, transformers, MLP. Evitar componentes exóticos sin probar.
- Regular agresivamente – Aplicar técnicas como dropout, aumento de datos, decaimiento de pesos.
- Normalizar entradas – Escalando características para tener media cero y varianza unitaria.
- Sintonizar hiperparámetros extensivamente – Barrido de tasa de aprendizaje, tamaño de lote, optimizadores es clave.
- Usar transfer learning – Inicializar partes del modelo con pesos pre-entrenados cuando sea posible.
- Escalar conjuntos de datos – Recopilar el conjunto de entrenamiento más grande posible con aumento de datos.
Combinar ambas técnicas también es poderoso. Por ejemplo, pre-entrenar módulos clave como codificadores y decodificadores desde cero, luego ajustar finamente todos los pesos del modelo.
Ejemplos del Mundo Real
A continuación se muestran algunos ejemplos del mundo real del uso efectivo del ajuste fino y el entrenamiento desde cero:
Ejemplos de Ajuste Fino
- BERT Ajustado Fino para Detección de Toxicidad – Investigadores ajustaron finamente el modelo de lenguaje BERT para identificar comentarios tóxicos en línea. El ajuste fino proporcionó un rendimiento robusto con solo ~100,000 ejemplos de entrenamiento.
- ResNet Ajustado Fino para Imagenes de Satélite – Ingenieros adaptaron el modelo de visión artificial ResNet pre-entrenado en ImageNet para analizar fotos de satélites. El ajuste fino permitió una clasificación precisa de imágenes con datos de satélite etiquetados limitados.
- Control de Robótica Usando ALE – Investigadores ajustaron finamente el agente de juego ALE para controlar brazos robóticos del mundo real adaptando solo las últimas capas. Esto transfirió el conocimiento de la simulación del juego a robots reales con un entrenamiento mínimo.
Ejemplos de Entrenamiento desde Cero
- Plegado de Proteínas AlphaFold de DeepMind – AlphaFold de DeepMind logró avances revolucionarios en la predicción de estructuras de proteínas a través de una extensa innovación de modelos de aprendizaje profundo y entrenamiento desde cero en grandes conjuntos de datos bioquímicos.
- Asistente de IA Claude de Anthropic – Anthropic entrenó el modelo conversacional Claude desde cero en diversos datos de texto de Internet. Este entrenamiento especializado permitió una fuerte capacidad de conversación que supera las alternativas de ajuste fino.
- MuZero de DeepMind – MuZero logró el estado del arte en Go, ajedrez, shogi y juegos de Atari entrenando agentes de aprendizaje por refuerzo desde cero. Esto mejoró el trabajo previo de ajuste fino de modelos de aprendizaje supervisado.
Como demuestran estos ejemplos, los resultados del mundo real validan las fortalezas centrales de ambas técnicas. Pensar cuidadosamente en combinar la eficiencia del ajuste fino con la personalización del entrenamiento desde cero proporciona un enfoque poderoso.
Ideas Clave y Conclusiones
Resumamos las lecciones clave sobre el ajuste fino versus el entrenamiento desde cero:
- El ajuste fino sobresale dado datos y tiempo de entrenamiento limitados, mientras que el entrenamiento desde cero se beneficia de grandes conjuntos de datos y cómputo extensivo para una personalización completa.
- Considere factores como los datos disponibles, la similitud del problema, el tiempo de entrenamiento, el acceso al hardware y las necesidades de personalización al elegir un enfoque.
- Equilibre los bloques de construcción de pre-entrenamiento desde cero con el ajuste fino del modelo completo para lograr eficiencia y personalización.
- Ningún enfoque es universalmente superior: elija en función de sus restricciones, recursos y requisitos de rendimiento específicos.
- Emplee técnicas como normalización por lotes, regularización agresiva, normalización de entrada y amplia optimización de hiperparámetros para maximizar el éxito.
En la era del aprendizaje profundo, aprovechar el conocimiento previo a través del ajuste fino y expandir el conocimiento mediante el entrenamiento desde cero son dos herramientas invaluables en el conjunto de herramientas de un profesional. Aprenda a combinarlos de manera efectiva en función de sus objetivos para crear modelos óptimos.
La idea clave es sopesar cuidadosamente los compromisos de cada enfoque con las necesidades de su proyecto. Con experiencia, aprenderá cuándo recurrir a un modelo pre-entrenado frente a diseñar su propia arquitectura personalizada. ¡Desarrollar este juicio le servirá bien para navegar el siempre cambiante panorama del aprendizaje profundo!
Próximos Pasos y Recursos Relacionados
Para obtener más información sobre el ajuste fino y el entrenamiento de modelos de aprendizaje profundo desde cero:
- Lea artículos y publicaciones de blogs que detallan técnicas avanzadas de ajuste fino y entrenamiento [LINK]
- Revise repositorios de código y tutoriales que implementan ambos enfoques [LINK]
- Ejecute experimentos que comparen modelos de ajuste fino y entrenamiento desde cero en conjuntos de datos abiertos [LINK]
- Siga los modelos e investigaciones de vanguardia que impulsan innovaciones en ambas técnicas [LINK]
¡Gracias por leer! Por favor comparta cualquier pregunta o idea sobre el ajuste fino versus el entrenamiento
Si quieres leer más contenidos interesante sobre inteligencia artificial o sobre otras tecnologias y su impacto sobre la economia e empresas entonces visita nuestro blog.





")