¡Bienvenido a nuestro articulo sobre los 10 pasos para aprender ciencia de datos con Python! Tanto si eres principiante como si buscas mejorar tus habilidades, esta guía te proporcionará una hoja de ruta para dar el pistoletazo de salida a tu viaje por la ciencia de datos.»
Contenidos: 10 pasos para aprender ciencia de datos con Python
Pasos para aprender ciencia de datos con Python
Paso 1: Averigua qué necesitas aprender
aprender ciencia de datos con Python
La ciencia de datos es un campo muy amplio, por lo que es importante identificar las áreas específicas en las que quieres centrarte, como estadística, aprendizaje automático o visualización de datos. La visualización de datos es una parte fundamental de la ciencia de datos.
Consiste en representar gráficamente la información y los datos para poder comprenderlos de manera más intuitiva. Al utilizar elementos visuales como gráficos, cuadros y mapas, podemos identificar rápidamente tendencias y patrones en los datos. La visualización de datos nos permite contar historias con un propósito, comunicar de manera efectiva los resultados de nuestro análisis y tomar decisiones informadas.
En el campo de la ciencia de datos, también es importante aprender a manipular y analizar datos utilizando herramientas como pandas, una biblioteca de Python que facilita la limpieza, exploración y transformación de datos. Además, el aprendizaje automático o machine learning es otro aspecto clave de la ciencia de datos.
Consiste en desarrollar algoritmos y modelos que permiten a las máquinas aprender y tomar decisiones basadas en los datos.
Paso 2: Familiarizarse con Python
aprender ciencia de datos con Python
Python es un lenguaje de programación popular para la ciencia de datos. Empieza por aprender los conceptos básicos de Python, incluyendo variables, tipos de datos, bucles y funciones.
Python es un lenguaje de programación de alto nivel y de código abierto diseñado para ser fácil de aprender. Es uno de los lenguajes más populares para la ciencia de datos debido a su sintaxis clara y legible, y a su amplia gama de bibliotecas y herramientas para el análisis de datos.
Para empezar a aprender Python, es importante conocer los conceptos básicos, como las variables, los tipos de datos, los bucles y las funciones. Las variables son contenedores que almacenan valores, como números o cadenas de texto. Los tipos de datos incluyen números, cadenas de texto, listas y diccionarios. Los bucles y las funciones son herramientas que te permiten automatizar tareas y reutilizar código.
Una vez que hayas aprendido los conceptos básicos de Python, puedes empezar a explorar las bibliotecas y herramientas específicas para la ciencia de datos, como pandas, NumPy, Matplotlib y scikit-learn.
Estas bibliotecas te permiten manipular y analizar datos, crear visualizaciones y construir modelos de aprendizaje automático.
Paso 3: Aprende análisis, manipulación y visualización de datos con pandas
aprender ciencia de datos con Python
Pandas es una potente biblioteca para la manipulación y el análisis de datos. Aprende a cargar, limpiar y explorar datos con pandas, y a visualizarlos con bibliotecas como Matplotlib o Seaborn. Pandas es una biblioteca de Python diseñada específicamente para facilitar el trabajo con datos. Es ampliamente utilizada en el campo de la ciencia de datos debido a su capacidad para manipular y analizar datos de manera eficiente.
Una de las primeras habilidades que debes adquirir al trabajar con pandas es aprender a cargar datos en un formato adecuado. Pandas te permite leer datos desde diferentes fuentes, como archivos CSV, Excel o bases de datos, y cargarlos en estructuras de datos llamadas DataFrames.
Una vez que hayas cargado los datos, es importante aprender a limpiarlos y prepararlos para su análisis. Pandas ofrece una amplia gama de funciones y métodos para realizar tareas como eliminar valores nulos, filtrar datos, cambiar el tipo de datos y realizar operaciones de transformación. Además de la manipulación de datos, pandas también es muy útil para explorar y analizar datos.
Puedes utilizar funciones como describe(), head(), tail() y value_counts() para obtener información estadística y resumida de tus datos. También puedes realizar operaciones de agrupación, filtrado y ordenamiento para obtener información más específica. Una vez que hayas realizado el análisis de datos, es importante poder visualizar los resultados de manera efectiva.
Pandas se integra con bibliotecas de visualización como Matplotlib y Seaborn, lo que te permite crear gráficos y visualizaciones atractivas para comunicar tus hallazgos de manera clara y concisa.
En resumen, aprender a trabajar con pandas te permitirá cargar, limpiar, explorar y visualizar datos de manera eficiente. Esta biblioteca es una herramienta fundamental en el campo de la ciencia de datos y te ayudará a realizar análisis más profundos y obtener información valiosa de tus datos.
Recuerda que la práctica constante y la exploración de diferentes conjuntos de datos te ayudarán a familiarizarte con pandas y a desarrollar tus habilidades en el análisis y manipulación de datos.
¡No dudes en inscribirte en cursos o tutoriales en línea para obtener una comprensión más profunda de pandas y su aplicación en la ciencia de datos!
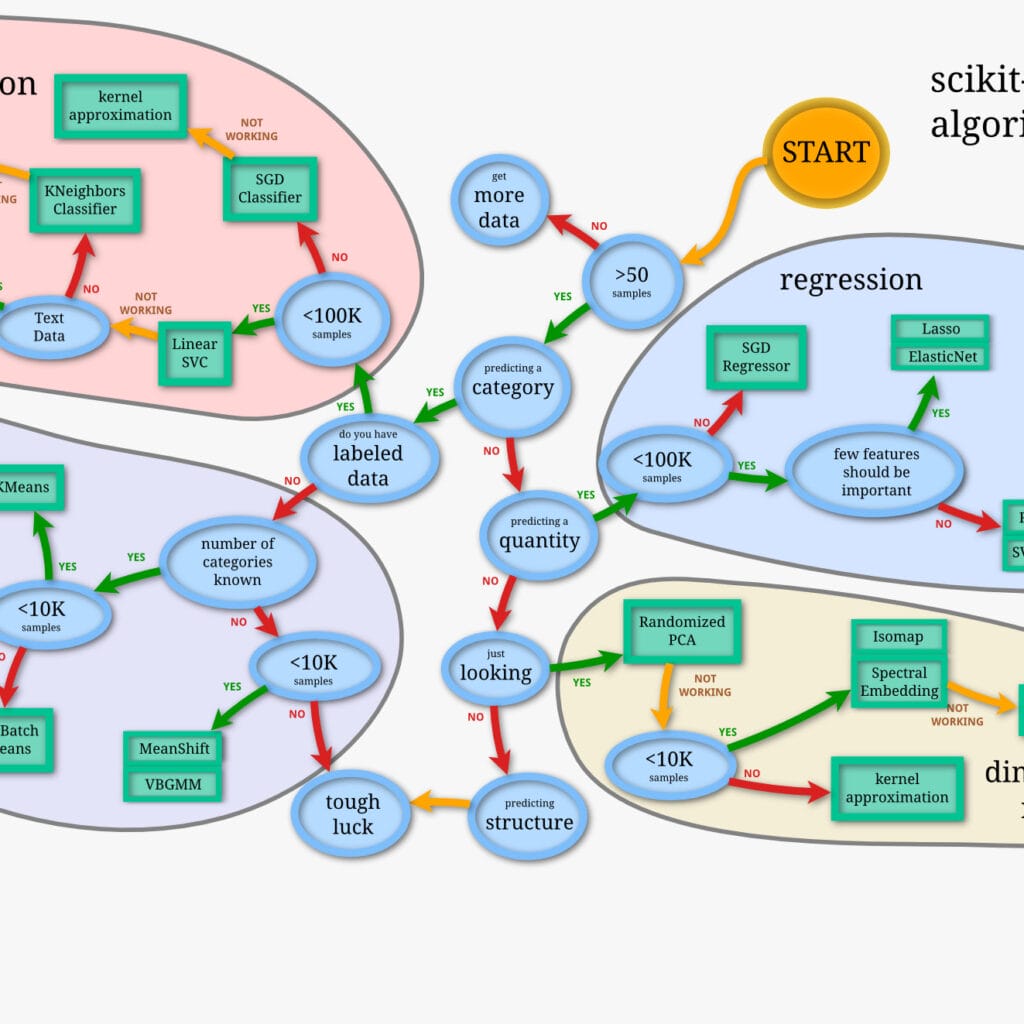
Paso 4: Aprende aprendizaje automático con scikit-learn
aprender ciencia de datos con Python
Scikit-learn es una biblioteca de aprendizaje automático ampliamente utilizada en Python. Aprende los fundamentos de los algoritmos de aprendizaje automático, como la regresión lineal, los árboles de decisión y las máquinas de vectores soporte.
Scikit-learn es una biblioteca de aprendizaje automático de código abierto en Python que proporciona una amplia gama de herramientas para el modelado y análisis de datos. Es una de las bibliotecas más populares utilizadas para el aprendizaje automático en Python debido a su facilidad de uso y a su amplia gama de algoritmos de aprendizaje automático.Para empezar a trabajar con scikit-learn, es importante aprender los fundamentos de los algoritmos de aprendizaje automático.
Algunos de los algoritmos más comunes incluyen la regresión lineal, los árboles de decisión y las máquinas de vectores soporte. Estos algoritmos se utilizan para resolver problemas de clasificación, regresión y agrupamiento.
Una vez que hayas aprendido los fundamentos de los algoritmos de aprendizaje automático, puedes empezar a explorar las funciones y herramientas específicas de scikit-learn. Scikit-learn ofrece una amplia gama de herramientas para el preprocesamiento de datos, la selección de características, la validación cruzada y la evaluación de modelos.
Además, scikit-learn se integra con otras bibliotecas de Python, como NumPy y pandas, lo que te permite trabajar con datos de manera eficiente y realizar operaciones de modelado de datos más complejas.En resumen, aprender a trabajar con scikit-learn te permitirá construir modelos de aprendizaje automático para resolver problemas de clasificación, regresión y agrupamiento.
Esta biblioteca es una herramienta fundamental en el campo de la ciencia de datos y te ayudará a realizar análisis más profundos y obtener información valiosa de tus datos.Recuerda que la práctica constante y la exploración de diferentes conjuntos de datos te ayudarán a familiarizarte con scikit-learn y a desarrollar tus habilidades en el aprendizaje automático.
¡No dudes en inscribirte en cursos o tutoriales en línea para obtener una comprensión más profunda de scikit-learn y su aplicación en la ciencia de datos!
Paso 5: Comprender el aprendizaje automático en mayor profundidad
aprender ciencia de datos con Python
Profundiza en conceptos de aprendizaje automático, como la evaluación de modelos, la selección de características y el ajuste de hiperparámetros. Explore algoritmos más avanzados como los bosques aleatorios, el aumento de gradiente y las redes neuronales.
Una vez que hayas aprendido los fundamentos del aprendizaje automático con scikit-learn, es importante profundizar en conceptos más avanzados. Algunos de estos conceptos incluyen la evaluación de modelos, la selección de características y el ajuste de hiperparámetros. La evaluación de modelos es un proceso crítico en el aprendizaje automático.
Es importante saber cómo medir la precisión de un modelo y cómo comparar diferentes modelos para determinar cuál es el mejor para un conjunto de datos específico. Algunas métricas comunes de evaluación de modelos incluyen la precisión, la sensibilidad, la especificidad y el área bajo la curva ROC. La selección de características es otro concepto importante en el aprendizaje automático. Se refiere al proceso de identificar las variables más importantes para un modelo y eliminar las que no son relevantes. Esto puede mejorar la precisión del modelo y reducir el tiempo de entrenamiento.
El ajuste de hiperparámetros es otro concepto avanzado en el aprendizaje automático. Los hiperparámetros son parámetros que no se aprenden automáticamente durante el entrenamiento del modelo, sino que se establecen antes del entrenamiento.
Ajustar los hiperparámetros adecuados puede mejorar significativamente la precisión del modelo. Además de estos conceptos avanzados, también es importante explorar algoritmos más avanzados en el aprendizaje automático.
Algunos de estos algoritmos incluyen los bosques aleatorios, el aumento de gradiente y las redes neuronales.
Estos algoritmos pueden ser más complejos que los algoritmos básicos de aprendizaje automático, pero también pueden proporcionar una mayor precisión en la predicción.
En resumen, profundizar en conceptos avanzados de aprendizaje automático como la evaluación de modelos, la selección de características y el ajuste de hiperparámetros, y explorar algoritmos más avanzados como los bosques aleatorios, el aumento de gradiente y las redes neuronales, te permitirá mejorar tus habilidades en el aprendizaje automático y realizar análisis más profundos y precisos.
Paso 6: Practica con conjuntos de datos reales
aprender ciencia de datos con Python
Aplica tus conocimientos a conjuntos de datos reales. Kaggle es una gran plataforma para encontrar conjuntos de datos y participar en competiciones de ciencia de datos. Una vez que hayas aprendido los conceptos básicos de la ciencia de datos y el aprendizaje automático, es importante poner en práctica tus habilidades en conjuntos de datos reales. Esto te permitirá aplicar tus conocimientos a situaciones del mundo real y mejorar tus habilidades en la resolución de problemas.
Participar en competiciones de Kaggle te permite trabajar en problemas del mundo real y aplicar tus habilidades de ciencia de datos para resolverlos. También te permite colaborar con otros expertos en el campo y compartir tus propios proyectos con la comunidad.
Además de Kaggle, también puedes encontrar conjuntos de datos en otros lugares, como en repositorios de datos gubernamentales o en sitios web de investigación. Trabajar con conjuntos de datos reales te permitirá enfrentarte a desafíos del mundo real y mejorar tus habilidades en la ciencia de datos.
En resumen, practicar con conjuntos de datos reales es un paso importante para mejorar tus habilidades en la ciencia de datos. Kaggle es una gran plataforma para encontrar conjuntos de datos y participar en competiciones de ciencia de datos, pero también puedes encontrar conjuntos de datos en otros lugares.
Recuerda que la práctica constante y la exploración de diferentes conjuntos de datos te ayudarán a desarrollar tus habilidades en la ciencia de datos y a convertirte en un experto en el campo.
Paso 7: Aprende SQL para la manipulación de datos
aprender ciencia de datos con Python
SQL es esencial para trabajar con bases de datos. Aprende los conceptos básicos de SQL para consultar y manipular datos almacenados en bases de datos relacionales. SQL, o Structured Query Language, es un lenguaje de programación utilizado para administrar y manipular bases de datos relacionales.
Aprender SQL te permitirá interactuar con bases de datos y realizar consultas para extraer y manipular datos de manera eficiente. Para comenzar a aprender SQL, es importante comprender los conceptos básicos. Algunos de los conceptos clave incluyen:
Consultas SELECT: Las consultas SELECT son la base de SQL y se utilizan para recuperar datos de una base de datos. Aprenderás a especificar las tablas y columnas de las que deseas extraer datos, así como a aplicar condiciones y filtros para obtener resultados más específicos.
Manipulación de datos: SQL también te permite realizar operaciones de inserción, actualización y eliminación de datos en una base de datos. Aprenderás a agregar nuevos registros, modificar datos existentes y eliminar registros no deseados.
Cláusulas WHERE y ORDER BY: Estas cláusulas te permiten filtrar y ordenar los resultados de tus consultas. Puedes especificar condiciones para seleccionar solo los datos que cumplan ciertos criterios y ordenar los resultados según una columna específica.
Joins: Los joins te permiten combinar datos de múltiples tablas en una sola consulta. Aprenderás a utilizar diferentes tipos de joins, como inner join, left join y right join, para combinar datos relacionados de manera efectiva.
Además de los conceptos básicos, también es útil aprender sobre la optimización de consultas, la creación de índices y la gestión de transacciones en SQL.
Existen numerosos recursos en línea, como tutoriales, cursos y plataformas de práctica, que te ayudarán a aprender SQL. Algunas plataformas populares para practicar tus habilidades de SQL incluyen Kaggle, donde puedes encontrar conjuntos de datos reales y participar en competiciones de ciencia de datos, y YouTube, donde puedes encontrar cursos completos de SQL.
En resumen, aprender SQL es esencial para trabajar con bases de datos y manipular datos de manera efectiva. Aprender los conceptos básicos de SQL te permitirá realizar consultas, manipular datos y obtener información valiosa de las bases de datos relacionales. No dudes en explorar diferentes recursos y practicar con conjuntos de datos reales para mejorar tus habilidades en SQL.
Paso 8: Domina la visualización de datos
aprender ciencia de datos con Python
La visualización de datos es crucial para comunicar información de forma eficaz. Aprende a crear gráficos informativos y visualmente atractivos utilizando bibliotecas como Matplotlib, Seaborn o Plotly. La visualización de datos es una herramienta fundamental en la ciencia de datos. Permite presentar información de manera gráfica y fácil de entender, lo que facilita la identificación de patrones y tendencias en los datos.
Además, la visualización de datos es una forma efectiva de comunicar los resultados de un análisis de datos a un público no técnico. Para dominar la visualización de datos, es importante aprender a crear gráficos informativos y visualmente atractivos utilizando bibliotecas como Matplotlib, Seaborn o Plotly. Estas bibliotecas te permiten crear una amplia variedad de gráficos, desde gráficos de barras y líneas hasta gráficos de dispersión y mapas de calor.
Además de aprender a crear gráficos, también es importante aprender a elegir el tipo de gráfico adecuado para los datos que estás visualizando. Algunos tipos de gráficos son más adecuados para ciertos tipos de datos que otros. Por ejemplo, un gráfico de barras es adecuado para comparar diferentes categorías, mientras que un gráfico de líneas es adecuado para mostrar tendencias a lo largo del tiempo. Otro aspecto importante de la visualización de datos es la elección de colores y etiquetas. Los colores y etiquetas adecuados pueden hacer que un gráfico sea más fácil de entender y más atractivo visualmente.
Existen numerosos recursos en línea, como tutoriales, cursos y plataformas de práctica, que te ayudarán a aprender a dominar la visualización de datos. Algunas plataformas populares para practicar tus habilidades de visualización de datos incluyen Kaggle, donde puedes encontrar conjuntos de datos reales y participar en competiciones de ciencia de datos, y Tableau, una plataforma de visualización de datos líder en la industria. En resumen, dominar la visualización de datos es esencial para comunicar información de manera efectiva en la ciencia de datos.
Aprender a crear gráficos informativos y visualmente atractivos utilizando bibliotecas como Matplotlib, Seaborn o Plotly, y elegir el tipo de gráfico adecuado para los datos que estás visualizando, te permitirá presentar tus hallazgos de manera clara y concisa. No dudes en explorar diferentes recursos y practicar con conjuntos de datos reales para mejorar tus habilidades en la visualización de datos.
Paso 9: Mantente al día y sigue aprendiendo
aprender ciencia de datos con Python
La ciencia de datos es un campo en rápida evolución. Mantente al día de las últimas tendencias, técnicas y herramientas leyendo blogs, asistiendo a seminarios web y participando en comunidades en línea. La ciencia de datos es un campo en constante evolución, con nuevas técnicas y herramientas que surgen constantemente. Para mantenerse actualizado en el campo, es importante seguir aprendiendo y explorando nuevas tendencias y tecnologías.
Una forma de mantenerse actualizado es leer blogs y artículos en línea sobre ciencia de datos y aprendizaje automático. Hay numerosos blogs y sitios web que cubren temas relevantes en el campo, como nuevas técnicas de modelado, herramientas de visualización de datos y tendencias emergentes. Otra forma de mantenerse actualizado es asistir a seminarios web y conferencias en línea.
Estos eventos pueden proporcionar información valiosa sobre las últimas tendencias y herramientas en el campo, así como oportunidades para conectarse con otros profesionales en el campo. También es útil participar en comunidades en línea, como foros de discusión y grupos de redes sociales, donde puedes conectarte con otros profesionales en el campo y compartir información y recursos.
Además, es importante seguir practicando y explorando nuevos conjuntos de datos y problemas en el campo. La práctica constante te ayudará a mejorar tus habilidades y a mantenerse actualizado en las últimas tendencias y técnicas en la ciencia de datos.
Mantenerse actualizado y seguir aprendiendo es esencial para tener éxito en el campo de la ciencia de datos. Leer blogs, asistir a seminarios web y conferencias, participar en comunidades en línea y practicar constantemente te ayudará a mantenerse actualizado en las últimas tendencias y técnicas en el campo.
Paso 10: Crea un portafolio y muestra tu trabajo
aprender ciencia de datos con Python
Crea una cartera de tus proyectos de ciencia de datos para demostrar tus habilidades y conocimientos. Comparte tu trabajo en plataformas como GitHub o crea un sitio web personal para mostrar tus proyectos. Crear un portafolio de proyectos de ciencia de datos es una excelente manera de demostrar tus habilidades y conocimientos a posibles empleadores o clientes. Un portafolio bien diseñado puede ayudarte a destacar en un mercado competitivo y a demostrar tu experiencia en el campo. Para crear un portafolio de proyectos de ciencia de datos, es importante seleccionar proyectos que muestren tus habilidades y conocimientos en diferentes áreas de la ciencia de datos. Algunos ejemplos de proyectos que podrías incluir son análisis exploratorios de datos, modelos de aprendizaje automático, visualizaciones de datos y proyectos de minería de datos. Una vez que hayas seleccionado tus proyectos, es importante compartirlos en plataformas en línea como GitHub o crear un sitio web personal para mostrar tus proyectos. GitHub es una plataforma popular para compartir proyectos de ciencia de datos y permite a los empleadores y clientes ver tu código y colaborar en proyectos. Además de compartir tus proyectos en línea, también es importante presentarlos de manera efectiva. Asegúrate de incluir una descripción clara de cada proyecto, así como los objetivos, los métodos utilizados y los resultados obtenidos. También es útil incluir visualizaciones de datos y gráficos para ilustrar tus hallazgos. Existen numerosos recursos en línea, como tutoriales y cursos, que te ayudarán a crear un portafolio de proyectos de ciencia de datos efectivo. Algunas plataformas populares para compartir tus proyectos incluyen Kaggle, GitHub y Tableau. En resumen, crear un portafolio de proyectos de ciencia de datos es una excelente manera de demostrar tus habilidades y conocimientos en el campo. Selecciona proyectos que muestren tus habilidades en diferentes áreas de la ciencia de datos, compártelos en plataformas en línea y presenta tus hallazgos de manera efectiva. No dudes en explorar diferentes recursos y practicar con conjuntos de datos reales para mejorar tus habilidades en la ciencia de datos y crear un portafolio impresionante.
Conclusión: Aprender ciencia de datos con Python
En conclusión, aprender Data Science con Python es una tarea emocionante y desafiante. Los 10 pasos mencionados anteriormente son una guía útil para aquellos que desean comenzar en este campo. Desde aprender los conceptos básicos de Python hasta crear un portafolio de proyectos, estos pasos te ayudarán a desarrollar habilidades valiosas en la ciencia de datos.
Hay numerosos recursos en línea, como cursos, tutoriales y plataformas de práctica, que pueden ayudarte a aprender y mejorar tus habilidades en la ciencia de datos. Mantenerse actualizado y seguir aprendiendo es esencial para tener éxito en este campo en constante evolución.
Con dedicación y práctica, puedes convertirte en un experto en Data Science con Python y abrirte a un mundo de oportunidades emocionantes en el campo de la tecnología y la ciencia de datos.
It is actually a great and useful piece of info. I am glad that you shared this helpful info with us. Please stay us up to date like this. Thanks for sharing.













 como cientista de datos / Data Scientist")
")













