
Conozca algunos de los algoritmos de aprendizaje automático más conocidos en menos de un minuto cada uno.
Algoritmos de aprendizaje automático explicados en menos de 1 minuto cada uno
En este artículo podrás encontrar una explicación fácil de entender de algunos de los algoritmos de aprendizaje automático más conocidos, para que los puedas asimilar de una vez para siempre.
Regresión lineal

Uno de los algoritmos de aprendizaje automático más sencillos que existen, la regresión lineal se utiliza para hacer predicciones sobre variables dependientes continuas con el conocimiento de las variables independientes. Una variable dependiente es el efecto, en el que su valor depende de los cambios en la variable independiente.
Puede que recuerde la línea de mejor ajuste de la escuela: esto es lo que produce la Regresión Lineal. Un ejemplo sencillo es predecir el peso de una persona en función de su altura.
Regresión logística
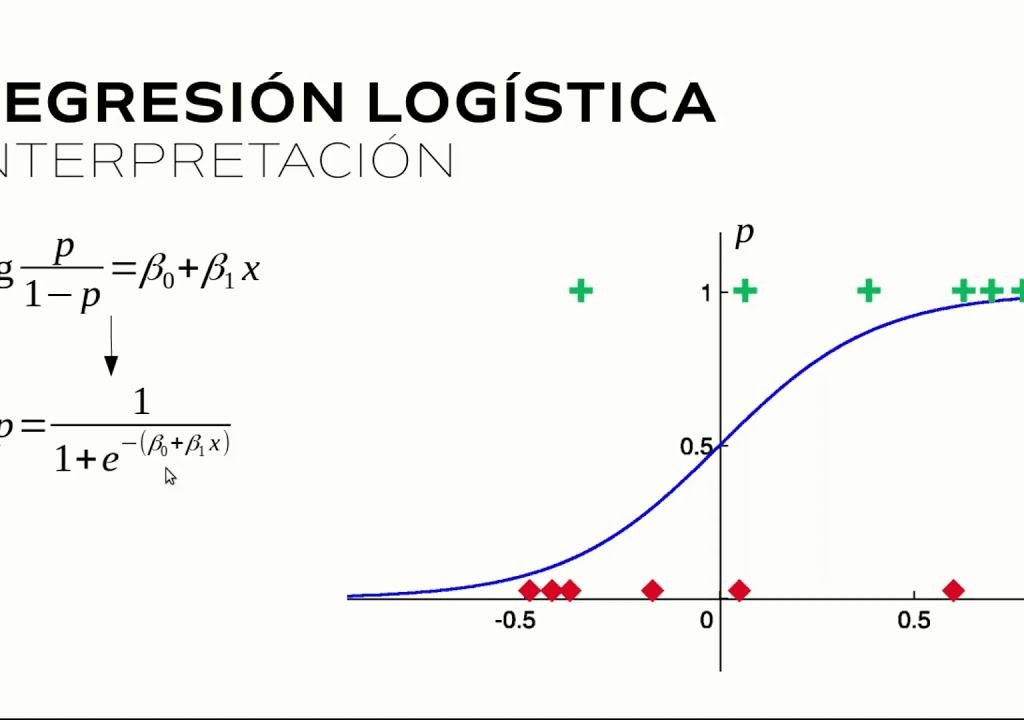
La regresión logística, similar a la regresión lineal, se utiliza para hacer predicciones sobre variables dependientes categóricas con el conocimiento de las variables independientes. Una variable categórica tiene dos o más categorías. La Regresión Logística clasifica resultados que sólo pueden estar entre 0 y 1.
Por ejemplo, se puede utilizar la Regresión Logística para determinar si un estudiante será admitido o no en una determinada universidad en función de sus calificaciones, ya sea Sí o No, o 0 o 1.
Árboles de decisión

Los Árboles de Decisión (DTs) son un modelo de estructura tipo árbol de probabilidad que divide continuamente los datos para categorizar o hacer predicciones basadas en el conjunto previo de preguntas que fueron respondidas. El modelo aprende las características de los datos y responde a las preguntas para ayudarle a tomar mejores decisiones.
Por ejemplo, puede utilizar un árbol de decisión con las respuestas Sí o No para determinar una especie específica de pájaro utilizando características de los datos como las plumas, la capacidad de volar o nadar, el tipo de pico, etc.
Random Forest(Bosque aleatorio)

Al igual que los árboles de decisión, el bosque aleatorio también es un algoritmo basado en árboles. Mientras que el árbol de decisión consiste en un árbol, el bosque aleatorio utiliza múltiples árboles de decisión para tomar decisiones: un bosque de árboles.
Combina múltiples modelos para realizar predicciones y puede utilizarse en tareas de clasificación y regresión.
K-Nearest Neighbors (K vecinos mas próximos)
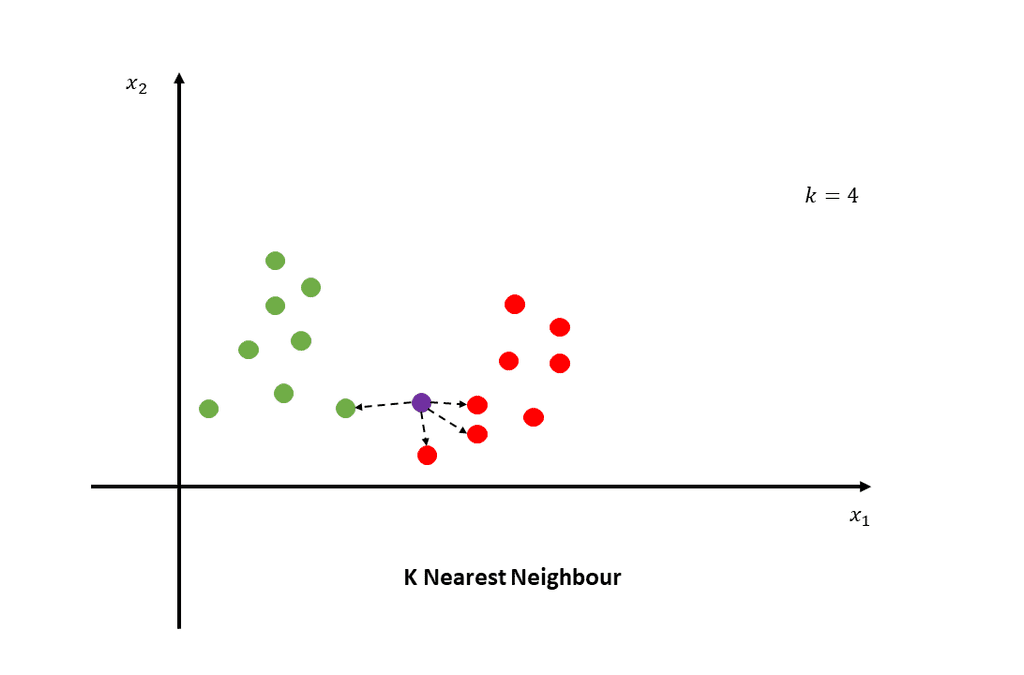
K-Nearest Neighbors utiliza el conocimiento estadístico de lo cerca que está un punto de datos de otro punto de datos y determina si estos puntos de datos pueden agruparse. La cercanía de los puntos de datos refleja las similitudes entre ellos.
Por ejemplo, si tuviéramos un gráfico con un grupo de puntos de datos cercanos entre sí llamado Grupo A y otro grupo de puntos de datos cercanos entre sí llamado Grupo B. Cuando introducimos un nuevo punto de datos, dependiendo del grupo al que esté más cerca el nuevo punto de datos, ése será su nuevo grupo clasificado.
Máquinas de vectores de Soporte ( Support Vector Machines)
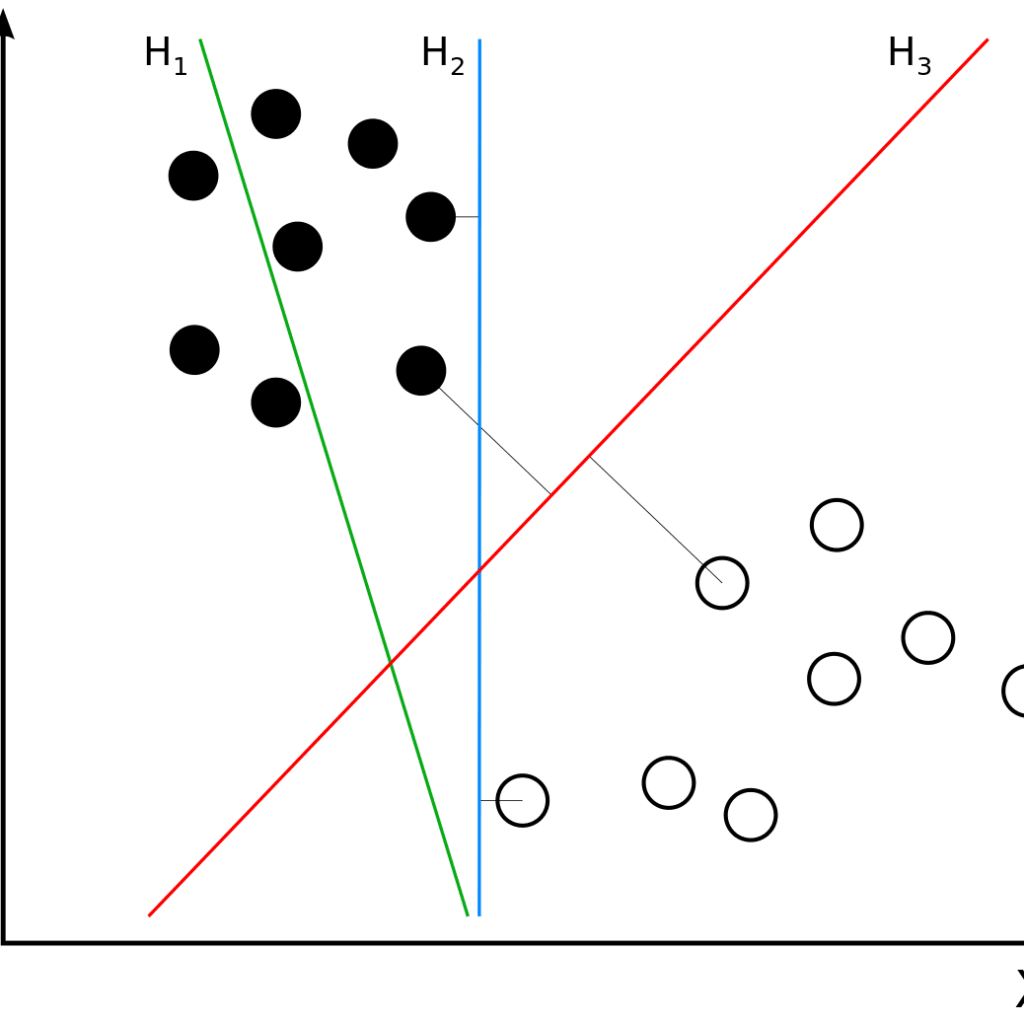
Al igual que el vecino más cercano, las máquinas de vectores de apoyo realizan tareas de clasificación, regresión y detección de valores atípicos. Lo hace dibujando un hiperplano (una línea recta) para separar las clases. Los puntos de datos situados a un lado de la línea se etiquetarán como Grupo A, mientras que los puntos situados al otro lado se etiquetarán como Grupo B.
Por ejemplo, cuando se introduce un nuevo punto de datos, según el lado del hiperplano y su ubicación dentro del margen, se determinará a qué grupo pertenece el punto de datos.
Naive Bayes
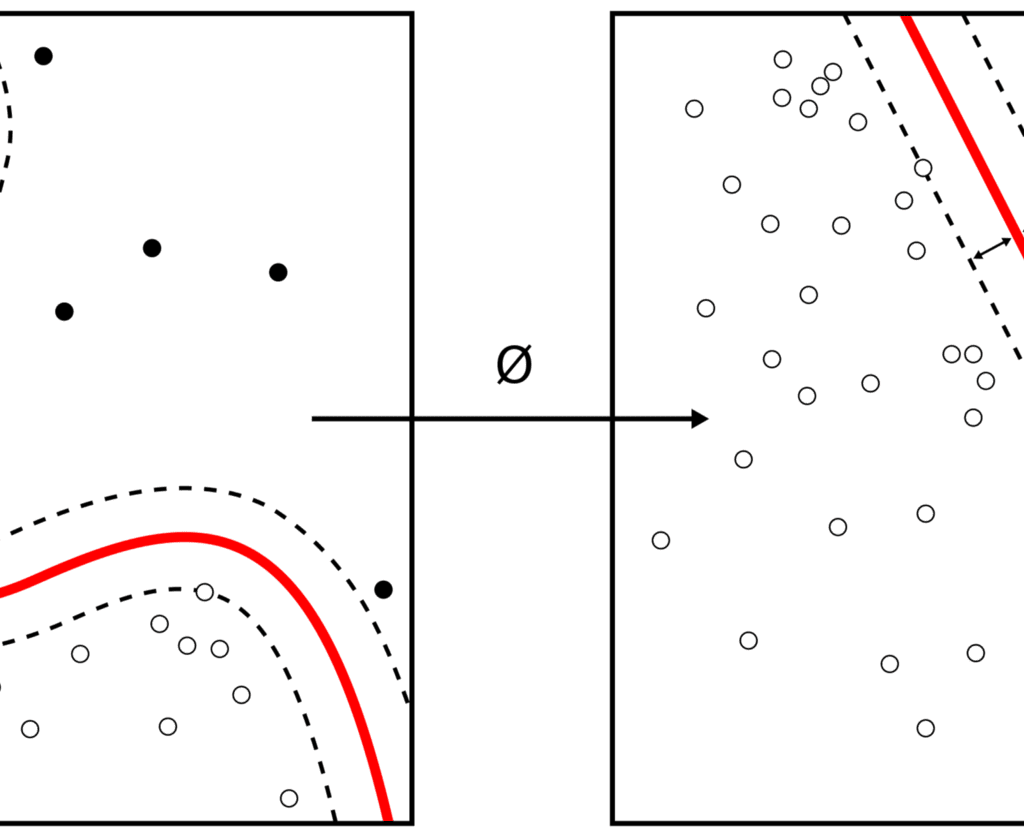
Naive Bayes se basa en el Teorema de Bayes, que es una fórmula matemática utilizada para calcular las probabilidades condicionales. La probabilidad condicional es la posibilidad de que se produzca un resultado dado que también se ha producido otro acontecimiento.
Predice que las probabilidades de cada clase pertenecen a una clase determinada y que la clase con la mayor probabilidad se considera la más probable.
Agrupación de k-means ( K-means Clustering)
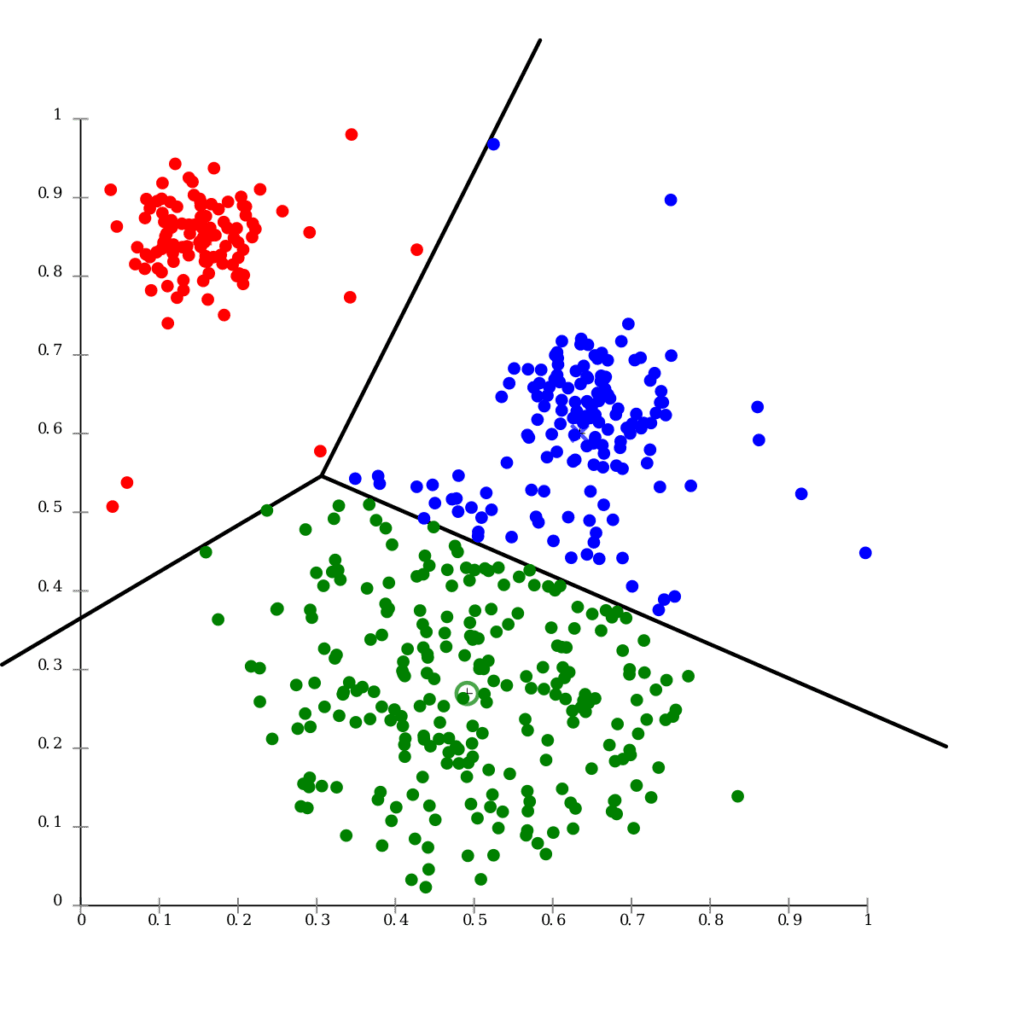
La agrupación de K-means, similar a la de los vecinos más cercanos, utiliza el método de agrupación para agrupar elementos/puntos de datos similares en clusters. El número de grupos se denomina K. Para ello, se selecciona el valor k, se inicializan los centroides y, a continuación, se selecciona el grupo y se encuentra la media.
Por ejemplo, si hay 3 clusters presentes y se introduce un nuevo punto de datos, dependiendo del cluster en el que caiga, ese es el cluster al que pertenecen.
Bagging

El bagging también se conoce como agregación Bootstrap y es una técnica de aprendizaje de conjunto. Se utiliza tanto en los modelos de regresión como en los de clasificación y su objetivo es evitar el sobreajuste de los datos y reducir la varianza de las predicciones.
El sobreajuste se produce cuando un modelo se ajusta exactamente a sus datos de entrenamiento, es decir, no nos enseña nada, y puede deberse a varias razones. Random Forest es un ejemplo de Bagging.
Boosting

El objetivo general del Boosting es convertir a los alumnos débiles en alumnos fuertes. Los aprendices débiles se encuentran aplicando algoritmos de aprendizaje de base que luego generan una nueva regla de predicción débil. Se introduce una muestra aleatoria de datos en un modelo y luego se entrena secuencialmente, con el objetivo de entrenar a los aprendices débiles e intentar corregir a su predecesor
En el Boosting se utiliza XGBoost, que significa Extreme Gradient Boosting.
Reducción de la dimensionalidad

La reducción de la dimensionalidad se utiliza para reducir el número de variables de entrada en los datos de entrenamiento, reduciendo la dimensión de su conjunto de características. Cuando un modelo tiene un gran número de características, es naturalmente más complejo, lo que conlleva una mayor probabilidad de sobreajuste y una disminución de la precisión.
Por ejemplo, si tiene un conjunto de datos con cien columnas, la reducción de la dimensionalidad reducirá el número de columnas a veinte. Sin embargo, necesitará la selección de características para seleccionar las características relevantes y la ingeniería de características para generar nuevas características a partir de las existentes.
La técnica de análisis de componentes principales (PCA) es un tipo de reducción de la dimensionalidad.
Conclusión
El objetivo de este artículo era ayudarle a entender los algoritmos de aprendizaje automático en los términos más sencillos. Si quieres conocer más a fondo cada uno de ellos, lee este artículo sobre Algoritmos de Aprendizaje Automático Populares.
Puedes ver más contenidos en nuestro blog
- Construyendo un Plan de Ciberseguridad Moderno para 2025: Guía Completa para CISOs
- La Revolución Silenciosa: Cómo la Inteligencia Artificial Impulsa la Sanidad del Mañana
- Probabilidad en ciencia de los datos
- Cursos Gratuitos de Ciberseguridad en Cisco
- Arquitecturas API: Patrones de Arquitectura con API Gateway para tu Aplicación












